Как подобрать ключевые слова для сайта
Лид — краткое введение и цель статьи
Семантическое ядро систематизирует ключевые слова и семантику сайта: подбор ключевых слов увеличит целевой трафик.

Почему ключевые слова важны — роль в SEO и бизнесе
Ключевые слова связывают поисковые запросы с целями бизнеса: отражают пользовательский интент — информационный интент или коммерческий интент — и задают релевантность страницы. Грамотная семантика привлекает целевой трафик и повышает конверсию.
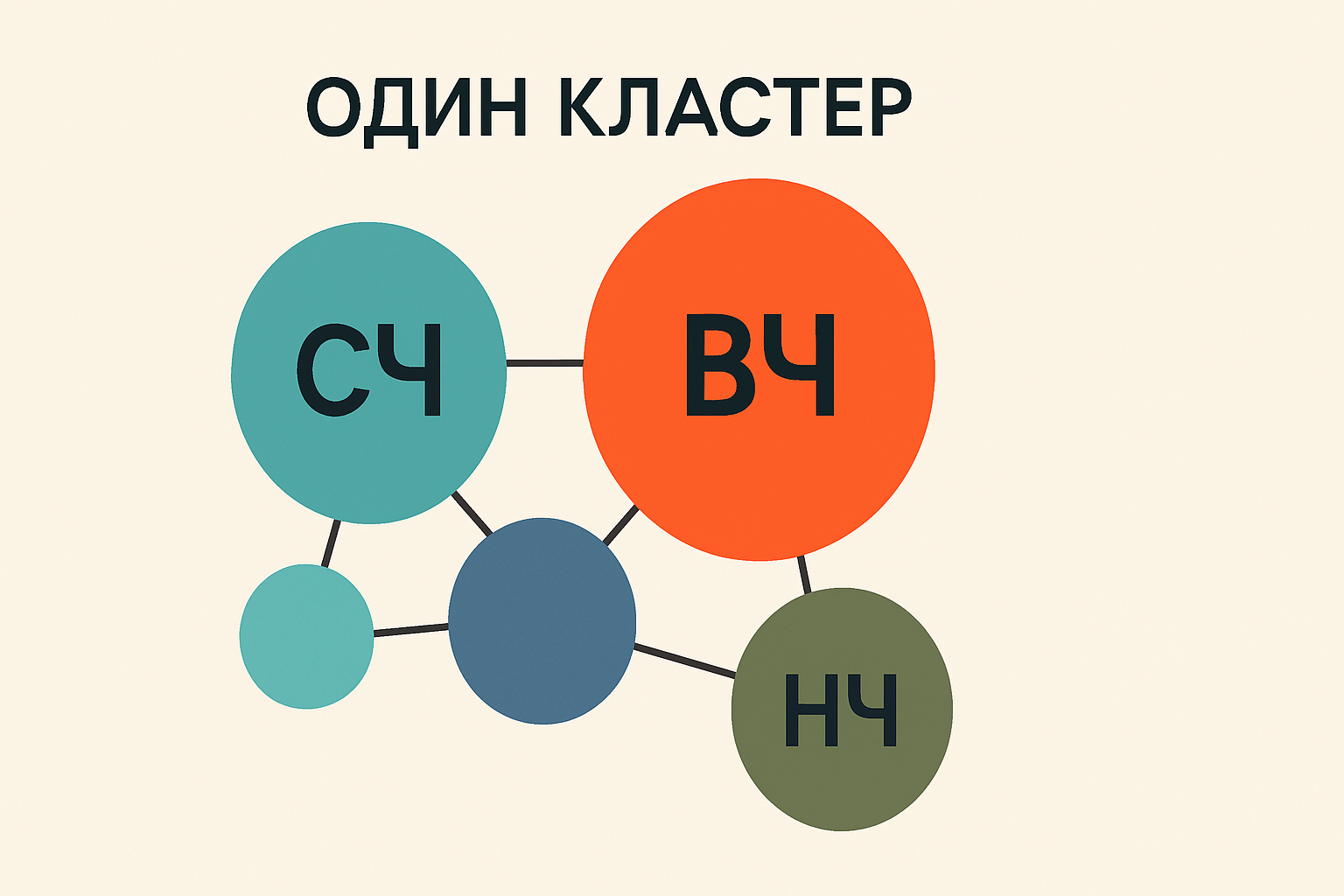
Классификация поисковых запросов: ВЧ/СЧ/НЧ и типы интента
Запросы делят на высокочастотные, среднечастотные и низкочастотные. ВЧ дают объём, но высокую конкуренцию; СЧ — компромисс; НЧ (длинный хвост, long-tail) приносят релевантный целевой трафик. Информационные запросы подходят для гайдов, коммерческие запросы — для карточек и лендингов, навигационные запросы — для страниц бренда; транзакционные — для покупок. Формат подбирают по интенту, чтобы повысить конверсию.
Пошаговый алгоритм сбора семантического ядра
Подбор ключевых слов начинается с тщательного майнинга seed‑фраз и парсинга подсказок: используйте подсказки поисковиков и инструменты для парсинг подсказок, чтобы собрать вариации. Затем проводите выгрузку в Яндекс.Wordstat и Wordstat‑ассистенты, анализируйте частота запросов и фильтруйте по минус‑словам и морфологии — нормализуйте словоформы и объединяйте синонимы. Оцените трудность (KD) каждой фразы и суммарную конкуренцию.
- Собрать seed
- Расширить подсказками
- Выгрузить частоты
- Убрать минусы
- Сгруппировать
- Оценить KD
Инструменты для сбора и анализа (список и что за что отвечает)
Набор инструментов нужен для майнинга ключей, экспорта частот и оценки KD/трудности. Ориентируйтесь на выгрузку CSV/Excel с частотой, объемом, конкурентностью и подсказками.
- Яндекс.Wordstat — частоты и подсказки (экспорт частот).
- Wordstat Assistant — парсинг подсказок, фильтры и массовые выгрузки.
- KeyCollector — майнинг ключей, объединение и нормализация словоформ.
- SEMrush — объём, KD, конкурентный анализ и SERP‑данные.
- Serpstat — частоты, кластеризация и аналитика конкурентов.
- Ahrefs — поиск ключей, оценка трудности (KD) и ссылочная аналитика.
- Topvisor — мониторинг позиций и сбор частот.
- Ubersuggest — генерация идей и оценка объёма/конкуренции.
- Keyword Planner — данные CPC и оценочные объёмы от Google Ads.
- Answerthepublic — идеи фраз и long‑tail (подсказки по интентам).
Кластеризация и группировка ключевых слов
Кластеризация ключевых слов помогает выстроить семантическую структуру сайта. Для семантической групировки применяют метод сетки, Разбивку по Кулакову и матрицу: объединяют запросы в кластеры по посадочным страницам и видимости в выдаче.
| Кластер | Примеры запросов | Частота (ВЧ/СЧ/НЧ) | Интент | Посадочная страница |
|---|---|---|---|---|
| Подбор ключей | как подобрать ключевые слова, подбор ключевых слов | СЧ/НЧ | Информационный | /kak-podobrat-klyuchevye-slova |
| Инструменты | KeyCollector, Яндекс.Wordstat, SEMrush | НЧ | Навигационный/Коммерческий | /instrumenty-dlya-seo |
Типы вхождений ключевых слов в тексте и на странице
Используйте разные типы вхождений: прямое вхождение и точное вхождение — в ключевых местах для сигнала релевантности; разбавленное вхождение и морфологическое вхождение помогают сохранить естественность текста. Распределяйте фразы осознанно в Title, Meta Description и H1, следите за плотностью ключевых слов и избегайте переоптимизации. Анкор и alt используют для внутренней перелинковки и релевантности изображений.
- Title
- H1
- H2/H3
- URL/человекочитаемый slug
- Meta Description
- Первый абзац (первичный абзац)
- alt атрибуты изображений
- Анкорные тексты внутренних ссылок
- Подписи к изображениям и подзаголовки
Плотность, TF/IDF и использование LSI‑терминов
Плотность основных ключей 1–3%, суммарно с LSI‑терминами — 3–6%; избегайте значений >7%. TF/IDF помогает выявить релевантные слова и приоритеты для семантического покрытия. Распределяйте LSI‑термины по вводному абзацу, заголовкам и основному тексту, чтобы сохранить естественность и равномерное покрытие тем.
Частые ошибки при сборе семантики и чек‑лист проверки
Типичные ошибки при сборе семантики: дубли страниц и отсутствие rel=canonical, неверные операторы в Wordstat, игнорирование интента, некорректная работа с минус‑словами, переоптимизация, пустые alt и слишком длинные meta description. Ниже — чек‑лист для финальной валидации.
- Проверить наличие и корректность rel=canonical
- Проверить meta description (длина, уникальность)
- Проверить alt у всех значимых изображений (нет пустых alt)
- Проверить список минус‑слов и операторы в Wordstat
- Исключить дубли страниц и канонические конфликты
- Проверить соответствие интента посадочным страницам
- Проверить плотность ключей и избегать переоптимизации
- Запустить финальный чек‑лист перед публикацией
Практические примеры и разбор кейса (таблица с результатами)
Краткий пример/кейс: от seed‑слов до групп и распределения по посадочным страницам. В таблице — запрос, частота, интент, кластер и предлагаемая посадочная страница для дальнейшей оптимизации.
| Запрос | Частота | Интент | Кластер | Посадочная страница |
|---|---|---|---|---|
| как подобрать ключевые слова | 1 200 | информационный | Подбор ключей | /kak-podobrat-klyuchevye-slova |
| KeyCollector обзор | 320 | коммерческий | Инструменты | /instrumenty/keycollector |
| Яндекс.Wordstat частота | 480 | навигационный | Инструменты | /instrumenty/wordstat |
| купить семантическое ядро | 90 | транзакционный | Услуги | /uslugi/semanticheskoe-yadro |
Технические требования и разметка
Ключевые технические элементы: корректные meta title и meta description (оптимальная длина), rel="canonical", meta robots (index, follow), OG/Twitter (og:image), alt у картинок, srcset и lazy loading, подключение Yandex.Metrika и Google Analytics, рекомендованная JSON‑LD (schema.org/Article) с author и date.
- meta title / meta description
- rel="canonical"
- meta robots: index, follow
- OG/Twitter + og:image
- JSON‑LD (Article, schema.org)
- alt у изображений, srcset и lazy loading
- Yandex.Metrika и Google Analytics
| Тег | Пример значения | Назначение |
|---|---|---|
| title | Как подобрать ключевые слова | Сниппет в выдаче |
| meta description | Пошаговый гайд по сбору СЯ | CTR в поиске |
| rel="canonical" | https://site.ru/kak-podobrat | Избежать дублей |
| meta robots | index, follow | Индексация страницы |
| og:image | https://site.ru/og.jpg | Превью в соцсетях |
| JSON‑LD | {"@type":"Article","author":"Имя"} | Структурированные данные (schema.org) |
| alt | Иллюстрация к кластеру | Доступность и контекст |
| analytics | Yandex.Metrika / GA | Сбор метрик и поведения |



Комментарии
Оставить комментарий